




What Is TF-IDF? Search Intent and Inverse Document Frequency


Each time a user types a search query into a search engine like Google, a complex network of algorithms leaps into action, working hard to deliver the most relevant search results. One of the foundational metrics these algorithms rely on to determine content relevance and value is TF-IDF.
But what is TF-IDF? And can you optimize for it?
To answer all your questions, in this guide, we
- define what TF-IDF is,
- explore its importance,
- and discover if TF-IDF is a ranking factor.
What Is TF-IDF?
TF-IDF, or Term Frequency-Inverse Document Frequency, is a numerical statistic pivotal to information retrieval. It’s used to gauge the importance of a word to a series of documents or corpus (a collection of written work).
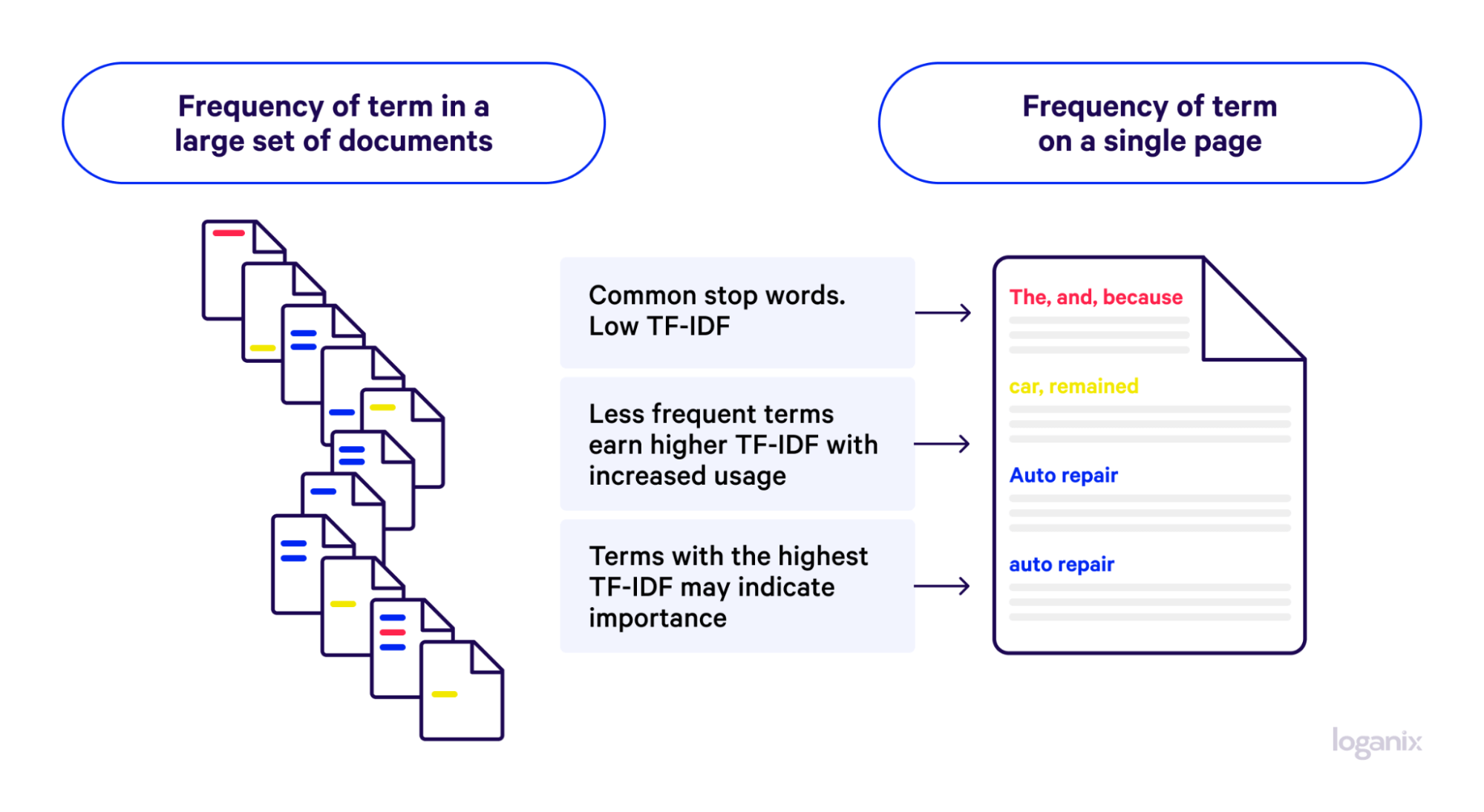
It works like this:
Term Frequency (TF)
Let’s say you’ve created a series of blog posts—a topic cluster—relevant to the search query “the best organic coffee beans.” If you count the amount each word “the,” “best,” “organic,” “coffee,” and “beans” appears in the cluster, you’ll have determined term frequency (TF).
However, this approach can be too simplistic. As you can imagine, a web page that is, say, 5,000 words in length will naturally contain the search query “the best organic coffee beans” more than a web page that is only 2,000 words. This is where term weighting comes in.
Term weighting adjusts for the length of the document. It suggests that the more “the best organic coffee beans” appear on a page relative to the length of that page, the more relevant that page is likely to be to a given search query. This way, longer documents don’t have an unfair advantage just because they contain more words.
Inverse Document Frequency (IDF)
However, there’s a caveat. Common words like “the” or “and” appear frequently in almost all English texts. If we were to rely solely on term frequency, a search engine algorithm might mistakenly assign undue importance to pages that frequently use these common words while overlooking pages that contain more meaningful, less common words like “organic,” “coffee,” and “beans.”
To rectify this, a factor known as the inverse document frequency (IDF) is employed. IDF diminishes the weight of terms that appear very frequently across multiple documents (like “the” or “and”) and amplifies the weight of terms that appear rarely (like “organic coffee beans”).
In essence, the less common the term, the more weight it carries in determining the relevance of a document to a specific search query. This ensures that the content that is truly relevant to the search query “the best organic coffee beans” is given the prominence it deserves in search results.
How is TF-IDF Calculated?
TF-IDF operates on a simple principle: the frequency of a word, phrase, or term within a document is assigned a value. This value is inversely proportional to the frequency of the word in the entire corpus of documents. In other words, the more frequently a term appears in a specific document but less frequently in the entire collection of documents, the higher its TF-IDF score will be.
The TF-IDF value increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general.
The calculation of TF-IDF involves two components:
- Term Frequency (TF) is the ratio of the count of a specific term to the total number of terms in the document. For example, if the term “the best organic coffee beans” appears 20 times in a 2,000-word article, the TF is 20/2000 = 0.01.
- Inverse Document Frequency (IDF) is calculated as the logarithm of the total number of documents in the corpus divided by the number of documents containing the specific term. If “the best organic coffee beans” appears in 100 out of 1,000 documents, the IDF is log(1,000/100) = 1.
The TF-IDF score is then the product of TF and IDF (0.01 * 1 = 0.01 in this case). This score represents the importance of “the best organic coffee beans” in the specific document relative to the entire corpus. A higher score indicates greater relevance. In our example, a score of 0.01 suggests low importance, while a score of, say, 0.46 indicates moderate importance.
Learn more: Interested in broadening your SEO knowledge even further? Check out our SEO glossary, where we’ve explained over 250+ terms.
Why Is TF-IDF Important?
TF-IDF plays a pivotal role in various fields, including machine learning, natural language processing, and search engine optimization. It transforms text into a numerical representation that can be processed by machine learning algorithms, enabling them to identify patterns and make sense of unstructured data.
In the context of search results, TF-IDF helps rank web pages based on their relevance to a specific query. This ensures that search engines deliver the most pertinent results to users’ queries. And in text summarization and keyword extraction, TF-IDF identifies the most significant words in a document. This aids in extracting key phrases and summarizing the content effectively.
TF-IDF: A Ranking Factor or Not?
TF-IDF, a ranking factor? Nope. While TF-IDF is a fundamental part of information retrieval, its direct impact as a ranking factor in search engine optimization (SEO) is debatable.
Evidence Against TF-IDF as a Ranking Factor
A renowned SEO expert, Joe Hall, argues that TF-IDF is not a magic metric for SEO. He suggests that other ranking factors, such as backlinks, likely have more significance than TF-IDF within the top search results. Joe summarizes his written piece by saying, “In my opinion, the best (and only) secret weapon to optimizing content for SEO is learning how to write well and quit chasing the algorithms.”
Google’s John Mueller explains in this video that “(TF-IDF) is a fairly old metric. And things have evolved quite a bit over the years. And there are lots of other metrics as well. So just blindly focusing on one kind of theoretical metric and trying to squeeze those words into your pages, I don’t think that’s a useful thing.”
John goes on to say, “Instead, I would strongly recommend focusing on your website and its users and making sure that what you’re providing is something that Google will, in the long term, still recognize and continue to use as something valuable. So, don’t just focus on artificially adding keywords. Make sure that you’re doing something where all of the new algorithms will continue to look at your pages and say, well, this is really awesome stuff. We should show it more visibly in the search results.”
Conclusion and Next Steps
When it comes to ranking your website’s content, here at Loganix, we take the same stance as Google—don’t write content for search engine algorithms. Instead, write content that’s relevant to search queries, helpful yet engaging, and is written for human readers, not Google crawlers.
🚀 Transcend outdated practices like keyword stuffing and, instead, balance SEO and user engagement—explore Loganix’s blog writing services today. 🚀
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Brody Hall on December 26, 2023
Content Marketer and Writer at Loganix. Deeply passionate about creating and curating content that truly resonates with our audience. Always striving to deliver powerful insights that both empower and educate. Flying the Loganix flag high from Down Under on the Sunshine Coast, Australia.