




How to Index Your Website on Google


If you aren’t getting any traffic, one big problem may be holding you back: your website or page isn’t indexed by Google 😱
Non-indexed pages are a serious issue.
It can make you invisible to all search engine users—even those looking for your site by name.
If you don’t appear in search engine results, you won’t receive any organic traffic. That can account for thousands of lost sales over the life of your site.
In this short guide, you’re going to learn what indexing is and how it happens. Then, you’re going to learn how to index websites on Google using the top troubleshooting methods.
What Does It Mean To Index Your Website?
Basically, is your site/page showing up on Google.
You don’t want to see a message like this:
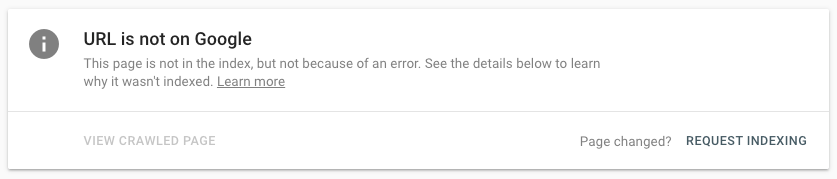
What you NEED to know about Google’s index:
- Your website is ‘indexed’ when Google adds it to their massive index of sites.
- The index is a database of all websites that have been approved to appear in searches, along with all (accessible) pages and content on those websites.
- Most indexing is complete within a few hours after you’ve moved it live, though it can take longer.
- Hundreds of thousands of websites are created every day, so the scanning process isn’t done by employees.
- Instead, the work is handled by programs known as crawlers.
- These programs have all the power over whether you’re indexed or not, so it’s important to understand how they work.
What are crawlers?
Crawlers (also known as robots or spiders) are automated programs that discover and scan websites.
Google crawls new content all the time as part of it’s algorithm. It uses dozens of proprietary crawlers to discover each page of your website or catalog images, videos, and ads.
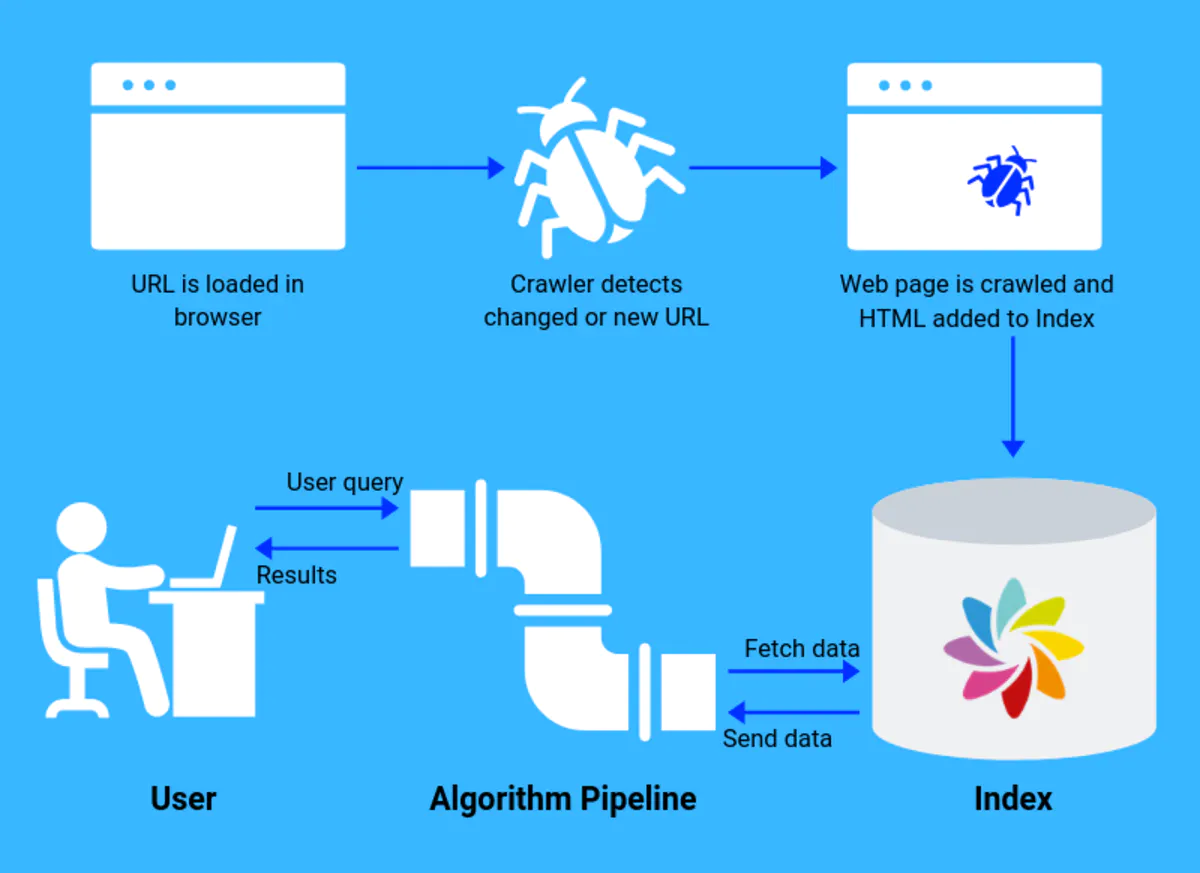
Source: https://www.sajari.com/blog/what-are-search-engine-crawlers/
These crawlers attempt to navigate your site the same way that a searcher does. They use menus and follow any links they can access. Naturally, content that they can’t access is not indexed.
Scanning is not a one-time process. Even indexed sites are continuously crawled by Google to determine if new pages have been added or if the content has been changed.
If Google hasn’t indexed your site, it’s possible that crawlers are the reason. However, the crawlers themselves are rarely the problem. More often, the problem is that your website is confusing them or unintentionally blocking their access.
Let’s look at some ways you can fix those problems and get the traffic you deserve.
How To Index a Website on Google
If your site, or specific pages on it, are not being indexed, there are some steps you can take to correct it.
The most effective troubleshooting steps are to:
- Request indexing directly
- Fill any gaps in your XML sitemap
- Remove unintended crawl blocks in your robots.txt file
- Remove unintended noindex tags
- Remove unintended canonical tags
- Remove unintended nofollow tags
- Verify that you haven’t orphaned your pages
- Improve the quality of the site or page
- Remove/block any pages you don’t want to improve
- Develop better backlinks/inbound links
You’ll learn more about each of these steps in just a bit.
TLDR: Get Indexed by Google (in 5 steps) 🔥
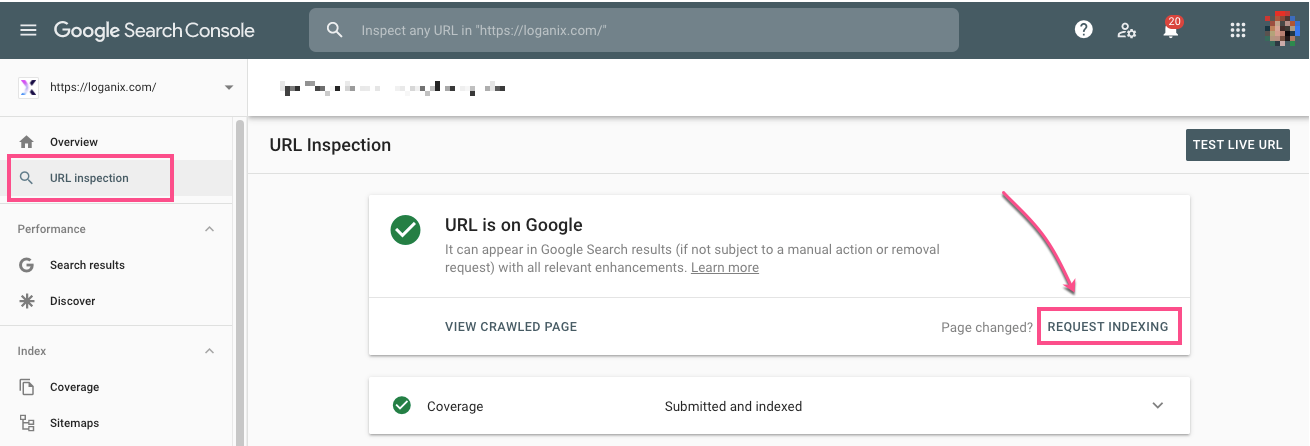
Follow these simple steps to get Google to crawl and index your site/pages:
- Open up Google Search Console
- Go to the URL inspection tool
- Paste into the search box the URL you want Google to index
- Wait until Google has checked the URL
- Now click the “Request indexing” button
Before you jump into troubleshooting ever possible indexation issue, you should make sure you’re troubleshooting the right problem.
Your first step should be to check your index status (if Google has indexed your site in the first place):
How can I tell if I’m indexed?
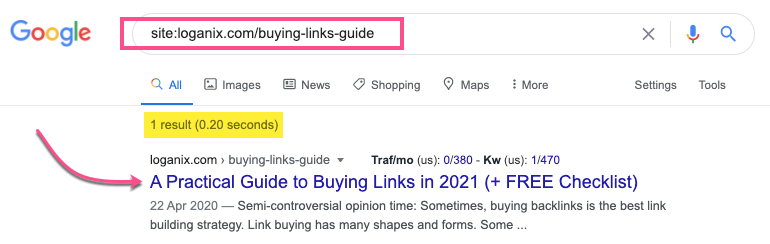
Go to Google and use the site: search operator, it looks like this:
site:websiteyouwanttocheck.com

This will show the approx number of your site pages Google has indexed.
You can also check the index status of a specific URL:
If you want to double-double check, Google offers an official way for you to determine if your site is indexed or not.
If you’ve ever asked yourself, “how does Google see my site?” this tool has the answer.
Visit the URL inspection tool on Google Search Console (or Google Webmaster Tools if you are old school) and follow the steps it lays out.
The whole process is guided once you’ve typed in an address, so it’s straightforward to get a yes or no answer. If the page you’ve looked up is indexed, you’ll find a message that reads: “URL is on Google,” or “URL is not on Google.”
If you get the second one, it’s time to start troubleshooting.
Simple (But Effective) Google Indexation Guide
Getting your site picked up by search engines doesn’t have to be complicated.
TLDR: 10 Ways To Index Your Pages 🔥
Check out these 10 ways to index web pages, new blog posts + other important pages:
- Request indexing directly
- Fill any gaps in your sitemap (or build one in the first place)
- Remove unintended crawl blocks in your robots.txt file
- Remove unintended noindex tags
- Remove unintended canonical tags
- Remove unintended nofollow tags
- Verify that you haven’t orphaned your pages
- Improve the quality of the site or page
- Remove/block any pages you don’t want to improve
- Build better backlinks
Let’s explore each of these indexing methods in more detail:
1. Request indexing directly
One of the first steps you can take is to request indexing directly. If you already looked up the URL using the inspection tool in the previous step, you already know where to find this option.
You’ll find the Request Indexing button at the end of the lookup.

You can also follow Google’s official instructions here. Requesting indexing will automatically queue your website to be crawled.
If this step doesn’t solve your problem, it means that there are likely problems on your site that need to be addressed. The following steps will help you address some of the most common ones.
2. Fill any gaps in your sitemap (or build one in the first place)
The sitemap is an XML file that lists all of your website’s pages and how they’re organized. The crawlers that we discussed earlier use the sitemap to get a better idea of where to go.
While a sitemap isn’t required for all sites, Google recommends them for sites that are large, new, or filled with rich media content.
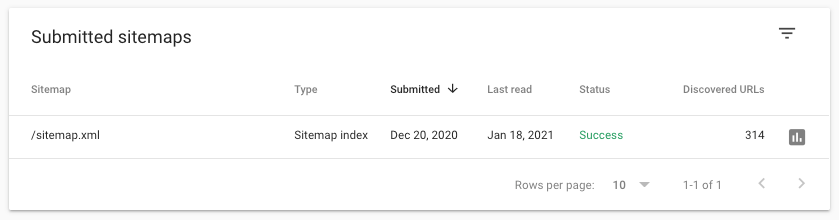
When sitemaps are sloppy or incomplete, crawlers will miss content. That can easily result in pages that don’t get indexed.
You can learn more about building and submitting a sitemap here.
3. Remove unintended crawl blocks in your robots.txt file
Your robots.txt file is located at yourdomain.com/robots.txt. It contains a list of rules for any robots (crawlers) that arrive on your website. Using these rules, it is possible to forbid crawlers from visiting certain pages—and this may be the source of your problem.
Visit the provided address and read the rules that are currently listed. Search for any that read:

These rules will prevent Googlebot (the primary crawler) or any crawlers from accessing certain pages. You may have put these rules in place while you were developing pages. If you bought your site, they might have been left there by the last owner of the site.
Either way, they can simply be deleted to solve the problem.
4. Remove unintended noindex tags
The noindex tag is an HTML meta tag that works much the same way as the blocks in the robots.txt file. To find out if you have any active, open the HTML for any given page and check the head section for code that reads:

Once again, simply removing the offending section will open the page up for crawling again.
5. Remove unintended canonical tags
A canonical tag is a tool that tells Google which version of a page you prefer when two pages cover similar information. It’s a good way to prevent duplicate content from being held against you.
However, canonical tags can sometimes be leftover from earlier versions of the site and point back to pages that no longer exist. When this happens, the crawler may not recognize any version of the page.
You can spot canonical tags in your sitemap, where they’ll look like this:

You can also use the URL inspection tool we covered earlier. This tool will tell you what page is considered canonical for any other given page.
Remove the tag to solve the problem.
6. Remove unintended nofollow tags
Nofollow tags are an attribute that you can add to links. When you place them, they prevent Google from passing any PageRank on to the linked page.

This tag is useful for outbound links, but you can also use them when internal linking.
When you use nofollow tags on internal links, crawlers won’t visit them. If you aren’t careful, this can cause some annoying problems.
One mistake you can easily make is blocking access to pages containing the only internal links to other pages. In other words, instead of blocking one page from being crawled, you block several of them.
The solutions are simple. Either remove the nofollow tag or add internal links to the stranded pages to other pages on your website.
7. Verify that you haven’t orphaned your pages
An orphaned page is a page that is no longer accessible because you’ve removed all of the access points.
Pages may become orphaned when you:
- Remove them from your site navigation
- Remove their parent pages
- Remove or nofollow their links on other pages
To find orphan pages, run your site through Screaming Frog and then go to Reports >>> Orphan Pages to download a list of lonely URLs:
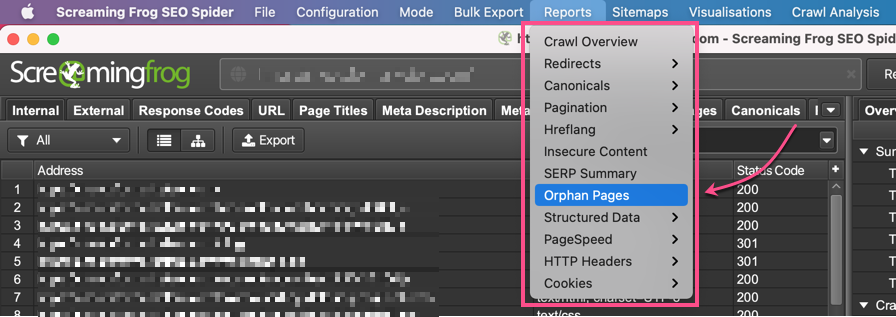
Crawlers have no way to access these pages, so they will not scan or index them. Hidden pages have a long history in black hat SEO, so Google doesn’t have a lot of motivation to correct this problem for you.
Fortunately, it’s an easy problem to fix. Just find a new place to link to your orphan pages from your existing pages. Request a fresh scan of your site from the index tool.
8. Improve the quality of the site or page
Crawlers are not just observers. They are empowered to pass judgment on pages and mark them as valuable or worthless.
Google has a policy of not indexing pages that don’t offer anything to readers. Fortunately, this is not a permanent condition. The page will continue to be crawled, and if you improve it for the better, it may be indexed in the future.
Improve page quality
Here are some quality changes you can make that will improve any page’s chance at being looked at in a better light:
- Add more quality content
- Make existing content more useful to readers
- Remove and replace any content that appears on other pages
- Remove and replace any content that’s duplicated from other sites
Once you’ve improved your page’s content, you can speed up the next review by requesting a review using the process you learned about in the first step.
9. Remove/block any pages you don’t want to improve
Google may choose to index or not index your site based on the site’s quality, overall.
If you have a slew of small pages, Google may determine that your entire site has nothing to offer visitors. If that happens, Google won’t index your site until you solve the problem.
It’s not always a good idea to remove these light pages. Depending on your site, you may need these pages to cover micro-topics that don’t belong on any other page.
You can make a judgment call and apply any of the following solutions:
- Remove the pages entirely
- Combine smaller pages into big resource pages
- Add nofollow tags to any internal links outside of your top pages
10. Build better backlinks
Crawlers can access your pages in a variety of ways. One of those ways is by following links from other domains to your website. The quality of these referring domains can play a role in how quickly your site gets indexed.
Enter: link building.
By collecting high-quality backlinks, you can improve the rate at which Google discovers your content. After all, your content is now being crawled every time a higher-tier website is crawled.
Take advantage of this by building out relevant backlinks.
4 Ways To Build *High Quality* Links
Here are some different resources to kickstart your link building:
Actionable SEO insights 🔍
Give us your site (or clients) and we’ll analyze the site’s SEO elements (on-page, URL equity, competitors etc), then organise this data into an actionable SEO audit.
Get in Google’s Index (to Get MORE Organic Traffic)
Organic traffic is one of the most significant sources of traffic for most websites. If you’re like most website owners, you can’t ignore this traffic source, which means you need to take indexing problems seriously.
Now, you have a set of solutions you can use to overcome the biggest obstacles to indexing. By correcting your code, improving your content, or improving the incoming links to your site, you can start appearing for searches.
Your next stop? Dominating the SERPs. Good luck.
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Jake Sheridan on January 21, 2021
Founder of Sheets for Marketers, I nerd out on automating parts of my work using Google Sheets. At Loganix I build products, and content marketing. There’s nothing like a well deserved drink after a busy day spreadsheeting.