




What Is JavaScript?


Getting Google to index JavaScript content is one of the more typical technical SEO issues that SEOs encounter.
JavaScript is becoming increasingly popular on the internet. It’s well-known that many websites struggle to generate organic growth because they overlook the value of JavaScript SEO.
Working on sites built using JavaScript frameworks (such as React, Angular, or Vue.js) will certainly present distinct problems than working on sites built with WordPress, Shopify, or other popular CMS platforms.
To achieve success in search engines, you must first understand how to verify whether your site’s pages can be displayed and indexed, discover problems, and make it search engine friendly.
In this article, we’ll teach you all you need to know about JavaScript.
What Is JavaScript?
JavaScript, abbreviated as JS, is a website scripting or programming language.
In a nutshell, JavaScript works with HTML and CSS to provide interaction that would otherwise be impossible. This includes dynamic visuals and sliders, interactive forms, maps, web-based games, and other interactive elements on most websites.
However, it is becoming more usual for complete websites to be created using JavaScript frameworks such as React or Angular, which can power both mobile and online apps. And the fact that these frameworks can create both single-page and multi-page web applications has increased their popularity among programmers.
JS is an interpreted language, which means that, unlike C or C++, it does not require a compiler to translate its code. JavaScript frameworks are sets of JavaScript libraries that give pre-written source code for developers to utilize for routine programming features and activities.
For many years, JavaScript was only supported by a small number of browsers. Microsoft Internet Explorer, the most popular browser, did not support JavaScript until much later.
JavaScript is also a very effective client-side programming language. JavaScript is mostly used to improve a user’s engagement with a webpage. To add more complex dynamic components to websites, many web developers now choose to use JavaScript frameworks such as jQuery. jQuery code may be combined to create more complex plugins. jQuery plugins are available from the jQuery UI (User Interface) library.
A primitive JavaScript engine included with a contemporary browser only offers a rudimentary set of APIs for program development. To carry out complex operations, such as building an Ajax-based request-response system.
Why Is JavaScript Important?
Developers will tell you that JavaScript is fantastic and will extol the virtues of AngularJS, Vue, Backbone, or React. They adore JavaScript because it enables them to develop extremely dynamic websites that users enjoy.
SEOs will tell you that JavaScript is frequently bad for your SEO performance, and they’ll even go so far as to suggest that JavaScript is job security for them while rapidly putting up statistics demonstrating dramatic declines in organic traffic once a site begins to rely on client-side rendering.
Both are correct.
At the same time, when engineers and SEOs collaborate well, they may generate fantastic outcomes. Even JavaScript-reliant websites may score well in search if they focus on providing the greatest possible experience for both users and search engines.
For a JavaScript-based website to do effectively in search, search engines must be able to completely grasp what your pages are about as well as your crawling and indexing guidelines from the initial HTML response.
JavaScript FAQ
Is JavaScript good for SEO?
Google and Bing recently released JavaScript-related SEO announcements, disclosing changes to simplify compatibility.
Google stated that they have begun utilizing the most recent version of Google Chrome to display webpages including JavaScript, Style Sheets, and other features.
Bing stated that the new Microsoft Edge will be used as the Bing Engine to produce sites.
Bingbot will now render all online pages using the same underlying web platform technology that Firefox, Googlebot, Google Chrome, and other Chromium-based browsers currently use.
Both major search engines have also said that they will make their solution evergreen by periodically updating their web page rendering engine to the most recent stable version of their web browser. These regular updates will assure support for the most recent features, which is a big improvement over prior versions.
Search engines are making SEO easier by using the same rendering technology. These Google and Bing advancements make it easy for web developers to guarantee that their websites and online content management systems function across both browsers without having to spend time researching each solution in depth.
The secondary content they see and experience in their new Microsoft Edge browser or Google Chrome browser is what search engines will likewise experience and view, with the exception of files that are not robots.txt banned.
This saves time and money for SEOs and developers. For instance,
- There is no longer any need to escalate to Bing.
- There is no longer a need to keep track of which JavaScript functions and style sheet directives operate with various search engines.
- There is no longer any need to maintain Google Chrome 41 on hand to test Googlebot.
- And the list could go on and on.
Does JavaScript hurt SEO?
To cut a long tale short, JavaScript can make it difficult for search engines to comprehend your page, allowing the opportunity for error and perhaps harming SEO.
When a search engine downloads and begins processing a web document, the first thing it does is determine the document type.
If the document is a non-HTML file (for example, an HTTP redirect, PDF, picture, or video), there is no need to display it using the JavaScript stack because this type of content does not include JavaScript.
If they have enough resources, they will attempt to render the HTML page using their optimal browser rendering methods for HTML files. When your JavaScript is not immediately integrated into the page, issues arise.
To read and execute the file, search engines must first download it. It won’t be able to if the content is blocked by robots.txt. If they are permitted, search engines must successfully download the content while dealing with crawl quota per site and site unavailability concerns.
Another risk is that the JavaScript file is out of sync with the cached version of the page. To avoid retrieving every resource on the page often, search engines typically cache for extended periods of time.
JavaScript may make HTTP requests to load content and extra resource files via HTTP calls, which increases the likelihood of encountering the previously described problems.
JavaScript contained in these JavaScript files or HTML may also be incompatible with search engines’ JavaScript engines. When it isn’t compatible, the search engine won’t read it, and if we can’t read it, we won’t remember it.
With the recent decision by search engines to utilize the same technology and the promise of browser vendors to update their browsers, this should become easier to deal with in the future.
Also, keep in mind that search engines’ support for JavaScript is limited:
- Use a # to search for normalized URLs. All parameters after the # are removed (excluding the legacy #! Standard).
- Search engines do not often click buttons or do other complicated activities.
- Search engines do not wait for sites to render for lengthy periods of time.
- Complex interactive web pages are not produced by search engines.
JavaScript should not be considered the new Flash! Keep in mind that every JavaScript instance must be read. When utilized in excess, it slows down the page speed for the ranking index.
How does Google use JavaScript?
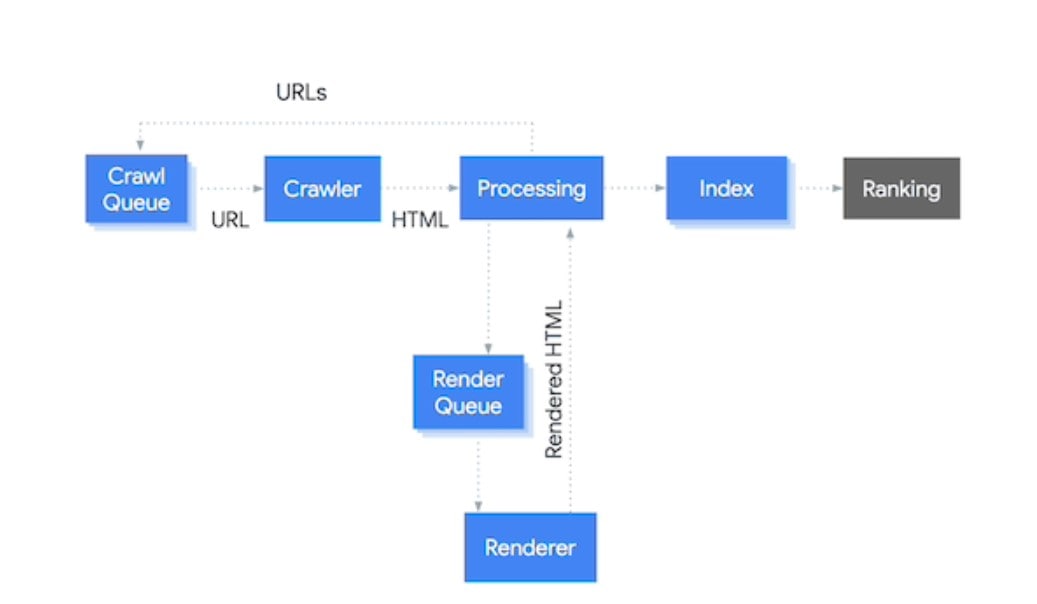
The diagram above theoretically describes Google’s operations from crawling to ranking. It has been considerably simplified; in fact, it involves thousands of sub-processes. We’ll go over each step of the process:
Crawl Line: It maintains track of every URL that needs to be crawled and is constantly updated.
Crawler: When the crawler (“Googlebot”) gets URLs from the Crawl Queue, it requests the HTML for those URLs.
Processing: The HTML is examined, and
- a) any URLs discovered are sent to the Crawl Queue for crawling.
- b) The necessity for indexing is determined—for example, if the HTML has a meta robots noindex tag, it will not be indexed (and hence will not be shown!). The HTML will be examined for new and updated content as well. The index is not updated if the content has not changed.
- c) The page’s dependency on JavaScript determines the requirement for rendering. URLs that must be rendered are queued up in the Render Queue. Please keep in mind that Google can already use the initial HTML answer while rendering is taking place.
- d) URLs have been canonicalized (note that this goes beyond the canonical link element; other canonicalization signals such as for example the XML sitemaps and internal links are taken into account as well).
Render Queue: It maintains track of every URL that has to be rendered and, like the Crawl Queue, it is constantly updated.
Renderer: When the renderer (Web Rendering Services, or “WRS”) gets URLs, it renders them and returns the generated HTML for processing. Steps 3a, 3b, and 3d are repeated, but this time the produced HTML is used.
Index: It examines text to evaluate relevancy, structured data types, and linkages, as well as (re)calculating PageRank and layout.
Ranking: The ranking algorithm uses information from the index to give the most relevant results to Google users.
So, instead of being able to directly pass URLs that need to be crawled to the Crawl Queue and forward information that needs to be indexed to the Index phase, Google must go through the entire rendering process in order to comprehend a JavaScript-reliant web page.
As a result, the crawling and indexing procedure is inefficient and sluggish.
What is JavaScript rendering?
When it comes to rendering JavaScript, there are several possibilities. For search engines, any type of SSR, static rendering, or prerendering configuration will suffice. The most problematic is complete client-side scripting, in which all rendering occurs in the browser.
To modify DOM components, Javascript uses the document object model (DOM). Rendering is the process of displaying the output in the browser. The DOM creates parent-child and neighboring sibling connections between the different components in the HTML file.
While Google is probably OK with client-side rendering, it is preferable to select an alternative rendering option to accommodate other search engines. Bing also supports JavaScript rendering, however, the extent of this support is uncertain. Yandex and Baidu have minimal support, while many other search engines have little to no support for JavaScript.
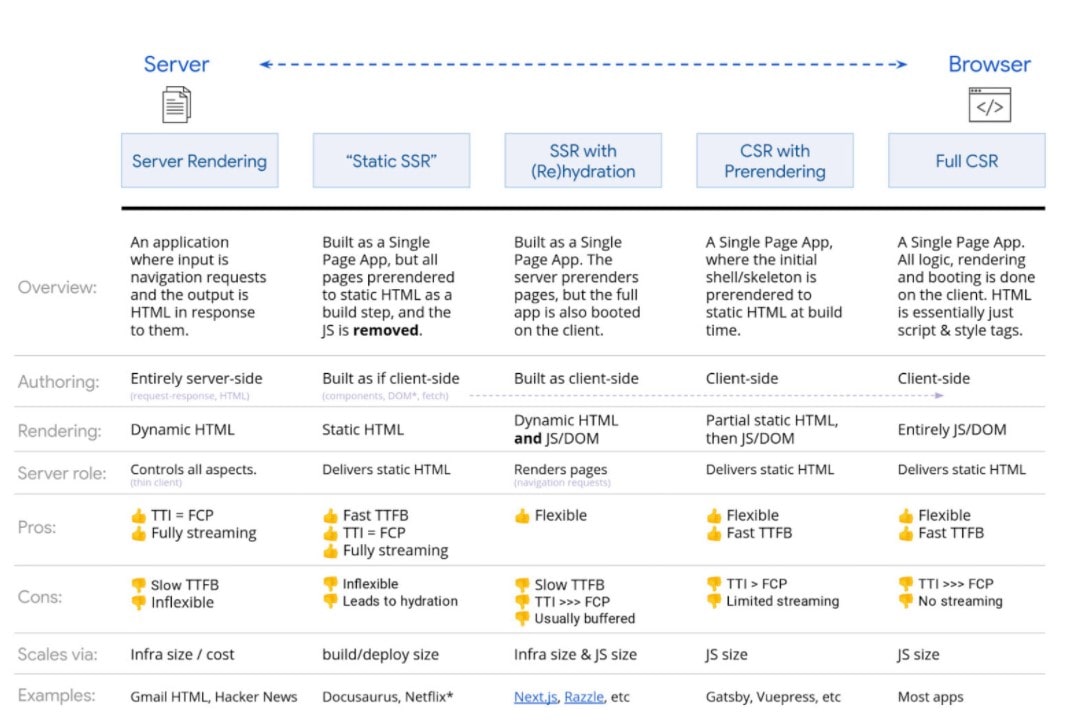
Google infographic rendering on the web
There is also Dynamic Rendering, which renders for certain user-agents. This is essentially a workaround, although it might be beneficial for rendering for specific bots such as search engines or social networking bots. Because social media bots do not support JavaScript, OG tags will not be visible unless you display the content before providing it to them.
If you were utilizing the previous AJAX crawling technique, please keep in mind that it has been deprecated and may no longer be maintained.
It is also critical that JS grows in strength on the server-side. This implies that studying Web development has one extra advantage.
Summary
Hopefully, this article has given you a better understanding of JavaScript.
It is better for SEO professionals if you do not produce JavaScript when search engine crawlers visit your webpages, provided the HTML text content and layout you return seem virtually identical to those viewed by humans visiting your sites.
It is OK to utilize JavaScript if it serves a purpose on the site and page. Make sure you understand the technical ramifications so that your pages can be correctly indexed, or seek the advice of a technical SEO specialist.
Search engines are compelled to index your content in order to please their customers.
If you come across any problems, use search engines webmaster online tools to examine them or contact them.
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Aaron Haynes on December 5, 2021
CEO and partner at Loganix, I believe in taking what you do best and sharing it with the world in the most transparent and powerful way possible. If I am not running the business, I am neck deep in client SEO.