




What Is Robots.txt? Master Crawler Directives for SEO Success

So you’ve heard whispers of this mysterious phenomenon called “robot.txt,” and you’re curious to know more.
This little-known gem plays a crucial role in how search engine crawlers interact with websites—it’s really very important.
To get you up to speed with everything robots.txt, in this guide, we provide answers to the questions:
- What is robots.txt?
- Why is it important?
- And how do you create a robots.txt file?
What is Robots.txt?
Robots.txt is a simple text file. You know it. The file format used when you create a Notepad file on a PC. However, in this case, instead of being used to create this weekend’s shopping list, a robots.txt file gives instructions to search engine crawlers (aka bots or spiders) about how they should behave when visiting a website.

Think of it as your website’s personal traffic cop, helping to maintain order and ensure crawlers only access the pages you want them to see. And as unassuming as it may seem, this tiny file plays a big role in helping search engines understand your site and index it correctly.
Learn more: what is a bot?
Why is Robots.txt Important?
Now that you know what robots.txt is, let’s dive into why it’s super important for your website:
- Control the crawl. As we just briefly touched on, with robots.txt, you can tell those search engine crawlers which parts of your site they should explore and which ones they shouldn’t.
- Save your crawl budget. Search engines have a limited amount of time they can spend crawling websites, known as the “crawl budget.”Using robots.txt allows you to optimize this budget by directing crawlers to the most important pages and keeping them away from the not-so-important ones.
- Protect sensitive info. Robots.txt helps you safeguard confidential or sensitive content on your site by blocking crawlers from accessing those areas. No snooping is allowed here.
- Avoid duplicate content issues. Duplicate content will likely negatively impact your search engine optimization (SEO) efforts. Thankfully, with robots.txt, you can prevent crawlers from indexing those pesky duplicates.
Learn more: what is indexing in SEO?
Robots.txt Syntax and Basic Directives
Alrighty, let’s get to the nitty-gritty of robots.txt syntax and some basic directives that you’ll definitely want to know. Don’t stress—it’ll be a piece of cake.
- First up, we’ve got the user-agent directive. This bad boy is like a name tag for search engine crawlers. You’ll use this to tell your robots.txt file which crawler(s) you’re talking to.
- Next on the list is disallow. You can use it to block specific directories or pages. For instance, “Disallow: /private/” is like saying, “Yo, crawlers, point your gaze somewhere else.”
- Now, let’s talk about allow. This directive does the exact opposite of “Disallow”—it gives the green light to crawlers for specific directories or pages, even if they’re within a disallowed area. It’s like saying, “Hey, you can come into this VIP section, just don’t touch anything.”
- The crawl-delay directive is like a speed limit for crawlers. It allows you to control how often a search engine crawler visits your pages, allowing it to crawl a maximum of 6 pages per minute or 8,640 pages per day maximum.
- Last but not least, we have the sitemap directive. This one’s a super helpful addition to your robots.txt file because it points crawlers to any XML sitemap(s) associated with a URL. Just add “Sitemap: https://www.example.com/sitemap.xml” to show them the way.
Learn more: SEO glossary 250+ terms explained.
How to Create and Upload a Robots.txt File
Let’s dive into how to create and upload a robots.txt file:
- Grab your favorite text editor (Notepad, Sublime Text, or whatever tickles your fancy) and create a new file. Just make sure to name it “robots.txt”—you know, ’cause that’s what we’re working on here.
- It’s time to add those directives. Remember? User-agent, disallow, allow, crawl-delay, and sitemap. So yeah, pop those bad boys in there, following the proper syntax we discussed earlier.
- Save your shiny new robots.txt file—it’s ready for its big debut.
- Now, to upload this gem. You’ll need access to your website’s root directory (think cPanel or FTP). Make sure to place the file right in there so it’s all cozy and easily found by search engine crawlers.
And voilà! You’ve successfully created and uploaded a robots.txt file. Give yourself a pat on the back ’cause you just leveled up your SEO game. 🚀
Note: To give you a quickfire explanation, we’re only scratching the surface here. If you want an in-depth breakdown, check out our comprehensive guide on how to create a robots.txt file for SEO.
Everyday Use Cases and Examples
Alrighty, let’s explore some nifty robots.txt use cases and examples. These should help you better understand how to wield this powerful tool to manage your website like a pro.
Blocking Specific Web Crawlers
Say you’ve got a pesky web crawler (we’ll call it “HackerBot”) that’s causing a ruckus on your site. No worries, just show them the door with a simple robots.txt directive:
- User-agent: HackerBot
- Disallow: /
This tells HackerBot to take a hike and stay away from your entire site.
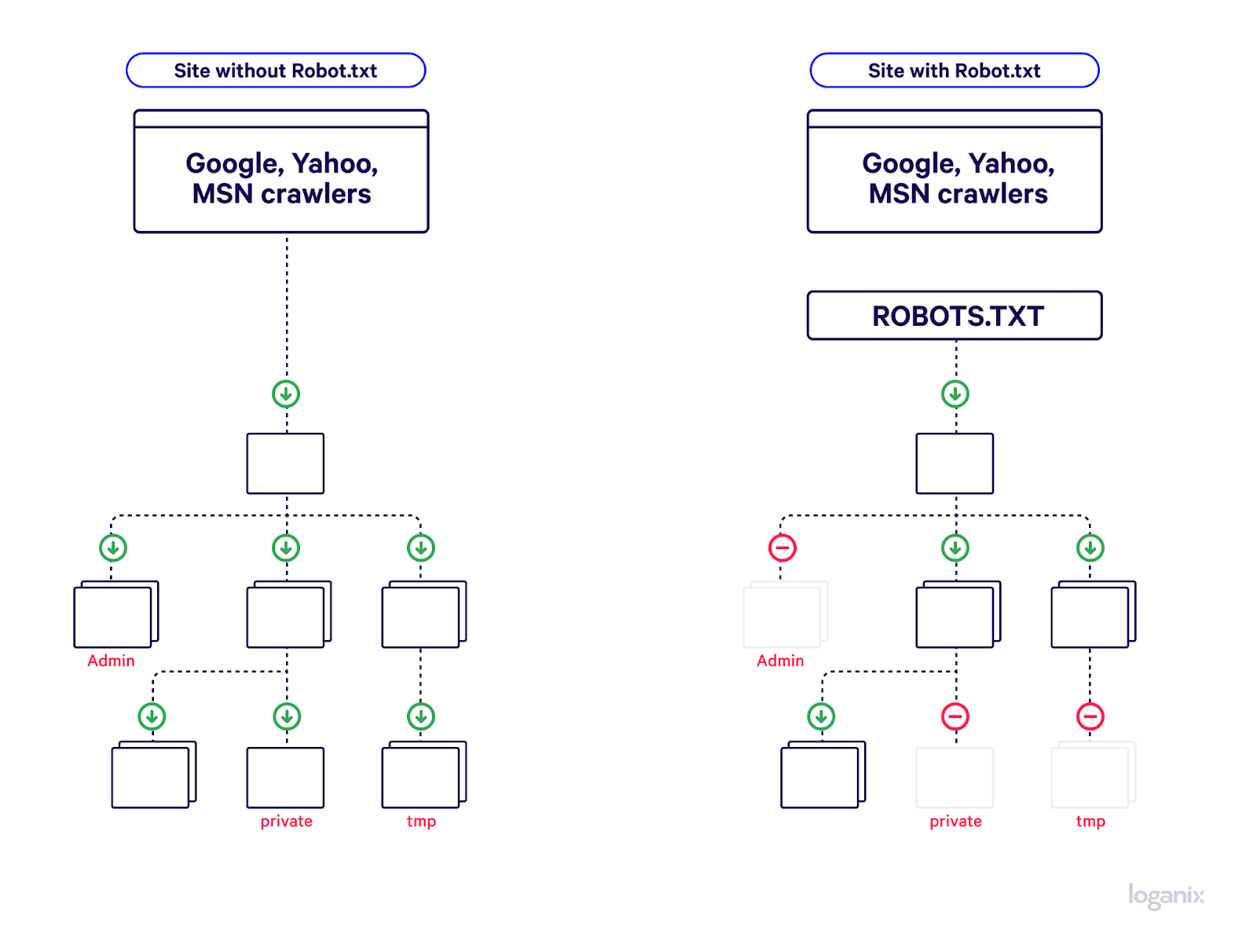
Allowing or Disallowing Access to Specific Folders or Web Pages
Do you have a top-secret web page that you want to keep under wraps? Just use robots.txt to block access:
- User-agent: *
- Disallow: /super-secret-folder/
- Disallow: /top-secret-web-page.html
This example tells all web crawlers (thanks to the “*” in User-agent) to steer clear of your secret folder and web page.
Managing Crawl Budget
If you’re worried about crawlers spending too much time on your site and hogging precious resources, you can set a crawl delay to give them a little breather:
- User-agent: *
- Crawl-delay: 10
With this directive, web crawlers will chill between requests for at least 10 seconds, helping you manage your crawl budget like a boss.
Learn more: what is crawl budget?
Robots.txt Best Practices
We’ve covered a lot so far, but now it’s time for the pièce de résistance—robots.txt best practices.
Proper Formatting and Syntax
First things first, make sure you’re using the right format and syntax. That means no typos or funky stuff that could throw off web crawlers. Keep it clean, like:
- User-agent: *
- Disallow: /private-stuff/
This example is simple, clean, and easy to understand. Nailed it!
Wildcards and Special Characters:
You can use wildcards like “*” to match any sequence of characters and special characters like “$” to match the end of a URL. For example:
- User-agent: *
- Disallow: /*?private
This rule prevents web crawlers from accessing any URL containing “?private”—super handy for blocking sneaky query strings.
Adding Comments
Like when using any code editing tool, don’t be shy about using comments to explain your directives. Just use the “#” symbol to add a comment like this:
- # Block access to private folders
- User-agent: *
- Disallow: /private-stuff/
Comments keep your robots.txt file organized and understandable, which is a total win-win.
Handling Subdomains and Separate robots.txt Files
Each subdomain on your site should have a robots.txt file. So, if you’ve got “blog.example.com” and “shop.example.com,” they each need their own robots.txt. Just upload the files to their respective root directories, and you’re golden.
Conclusion
Congratulations. You’re practically a robots.txt rockstar now.
But hey, it’s not just about knowing the deets—it’s about putting them into action.
And guess what? Loganix’s SEO services are here to help you take things to the next level. So whether you need help with your robots.txt or you’re looking to dominate search results, we’ve got your back.
👉 Click this shiny link to see a complete list of our SEO services. 👈
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Adam Steele on October 17, 2023
COO and Product Director at Loganix. Recovering SEO, now focused on the understanding how Loganix can make the work-lives of SEO and agency folks more enjoyable, and profitable. Writing from beautiful Vancouver, British Columbia.