




What Is Crawl Budget?


Google does not always crawl every page of a website in real-time. In fact, it might take weeks at times. This might jeopardize your SEO efforts. It is possible that your freshly optimized landing page or homepage will not get indexed.
This means it’s time to optimize your crawl budget.
Google must crawl a page before it may appear in search results and generate traffic to your site. Google indicates, “crawling is the entrance point for webpages into Google’s search results.”
In this article, you’ll understand what crawl budget means, its importance, how to calculate it, as well as learn how Google crawls a site.
What Is Crawl Budget?
Crawl budget is the number of pages Google crawls on your site each day.
This degree of focus is determined by how often search engines want to crawl and how frequently a website may be crawled.
The health of your URLs refers to how quickly your pages load for search engines if there are any status code problems on those sites, and whatever limitations you’ve put on your pages via Google Search Console or Google Analytics.
In general, Google allocates crawl budget based on four major factors:
- Site Size: Larger sites will need a larger crawl budget.
- Server Configuration: The performance and load times of your site may influence how much budget is allotted to it.
- Updates Frequency: How frequently do you update your content? Google will emphasize quality content that is regularly updated.
- Links: Internal links, backlinks/external links, and dead links
While crawl-related difficulties might hinder Google algorithms from seeing your site’s most vital information, it is critical to remember that crawl frequency is not a quality indicator.
Increasing the frequency with which Googlebot crawls your site will not help you rank higher.
If your content does not meet the expectations of your target audience, it will not attract new users. (And, while crawling is required to appear in the results, it is not a ranking factor.)
Crawl budget’s history
Google stated in 2009 that it could only locate a portion of the information on the internet and advised webmasters to optimize for crawl budget:
“The Internet is a vast space where fresh content is constantly being generated. Google has a limited number of resources, therefore when confronted with the almost unlimited amount of content available online, Googlebot can only discover and crawl a portion of it. Then, we can only index a fraction of the information we’ve crawled.”
Technical SEOs and webmasters began to discuss crawl budget more and more, prompting Google in 2017 to publish a blog post by Gary Illyes that described crawl budget precisely.
Why Is Crawl Budget Important?
A crawler, such as Googlebot, is given a list of URLs to crawl on a website. It works its way through the list in a methodical manner. It periodically checks your robots.txt file to ensure that it is still permitted to crawl each URL, and then crawls the URLs one by one. Once a spider has crawled a URL and digested its contents, it adds any new URLs identified on that page that it needs to crawl to its to-do list.
Several circumstances can cause Google to believe that a URL needs to be crawled. It might have discovered fresh links referring to content or it could have been tweeted, or it could have been updated in the XML sitemap, etc. There is no way to enumerate all of the reasons why Google might crawl a URL, but when it concludes that it must, it adds it to the to-do list.
According to statistics, Google misses around half of the pages on major websites.
To summarize, if Google does not index a page, it will not rank for anything.
As a result, if the number of pages on your site exceeds the crawl budget, you will have unindexed pages, resulting in poor SEO results. This is because:
- Crawlers utilize links on websites to find new pages. (The internal linking structure of your site is critical.)
- Crawlers rank new sites, updates to existing sites, and dead links in order of importance.
- An automated mechanism determines which sites to crawl, how frequently to crawl them, and how many pages Google will retrieve.
- Your hosting capabilities have an influence on the crawling process (server resources and bandwidth).
- Given the vastness of the internet, crawling the web is a difficult and costly operation for search engines.
With that at the back of your mind, there are a few instances where you should consider crawl budget:
- You manage a large website: If you have a website (such as an eCommerce site) with 10,000 or more pages, Google may have difficulty discovering them all.
- You’ve just added a bunch of new pages: If you’ve recently added a new section to your site with hundreds of pages, make sure you have enough crawl budget to have them all indexed promptly.
- There are several redirects: A large number of redirections and redirect chains deplete your crawl budget.
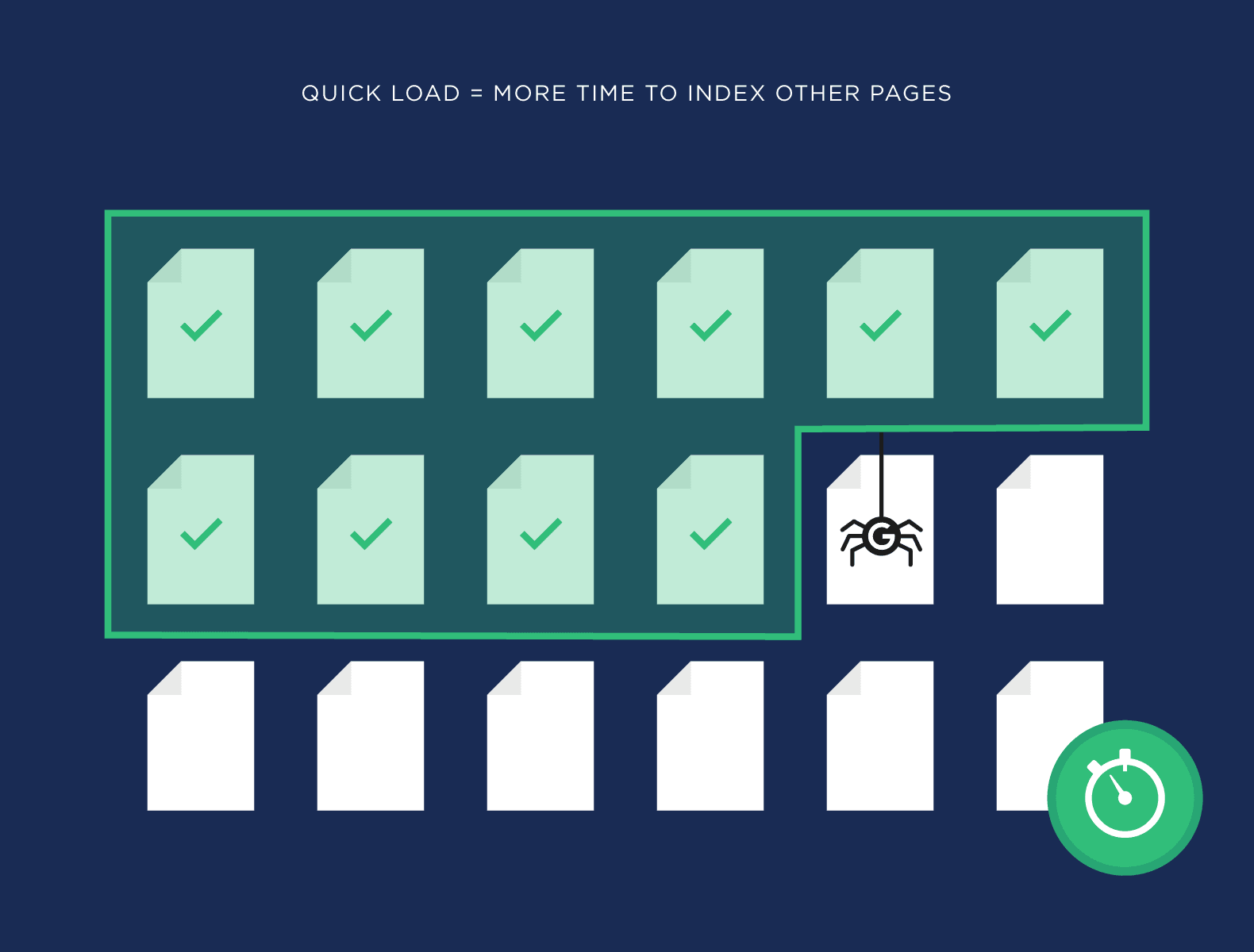
- Page speed is a ranking and user experience consideration, but it is also a crawl budget factor.
Crawl Budget FAQ
How do you calculate crawl budget?
Here’s how you can swiftly calculate whether your site has a crawl budget problem:
- Determine the number of pages on your site; the number of crawlable URLs in your XML sitemaps may be a suitable starting point.
- Navigate to Google Search Console.
- Go to “Legacy Tools” -> “Crawl Stats” and record the average number of pages crawled every day.
- Divide the total number of pages by the average number of crawled pages each day.
- If you wind up with a figure of more than ten (meaning you have ten times the amount of pages that Google crawls each day), you should optimize your site’s crawl budget. If you get a number less than three, consider you’re safe.
What does crawl budget mean for Googlebot?
Google calculates crawl budget by taking into account crawl rate limit and crawl demand.
Crawl limit
Googlebot is intended to be a decent web citizen. Its major objective is crawling while ensuring that it does not damage the user experience on the site. This is known as the “crawl rate limit,” and it restricts the maximum fetching rate for a specific site.
Simply put, this is the number of concurrent parallel connections Googlebot may utilize to scan the site, as well as the amount of time it must wait between fetches. The crawling pace can fluctuate depending on a number of factors, including:
- Crawl health: if the site answers rapidly for a period of time, the limit increases, implying that additional connections may be utilized to crawl. If the page load time decreases or the server answers with an error, the limit is reduced and Googlebot crawls less because of these error pages.
- Setting a limit in Google Search Console allows website owners to minimize Googlebot’s crawling of their site. It is important to note that increasing the crawling restrictions does not immediately enhance crawling.
Crawl demand
Even if the crawl rate limit is not reached, if there is little demand from indexing, Googlebot activity will be minimal. The two most important elements in influencing crawl demand are:
- Popular URLs: URLs that are more popular on the Internet are crawled more frequently to keep them fresh in our index.
- Staleness: Our technologies make every effort to keep URLs from getting stale in the index. Furthermore, site-wide events like site migrations may raise crawl demand in order to reindex the content under the new URLs.
That’s why crawl budget is defined as the number of URLs Googlebot can and wants to crawl when we combine crawl rate and crawl demand.
How long does it take for Google to crawl a site?
Your content must first be crawled before it can be indexed. The time it takes for your website to be fully crawled is determined by your site’s crawl budget – the amount of attention your site receives from Google.
It’s fascinating to examine your server logs to discover how frequently Google’s spiders visit your website. After it has been thoroughly crawled, the next stage is indexing. The following elements have a significant influence on indexing site speed:
- Reliance on client-rendered JavaScript, hreflang, or embedded content, such as CSS, on the webpage
- The caliber of your content
- The size of the webpage
As a general rule, we anticipate;
- 3–4 weeks for websites with fewer than 500 pages.
- For websites with 500 to 25,000 pages, it takes 2–3 months.
- For websites with more than 25,000 pages, the time frame is 4–12 months.
Of course, because each website is unique and is treated differently by Google, these estimations should be taken with a grain of salt. In the end, Google gets the last say on all things SEO.
Any URL that the Googlebot crawls will have an impact on the crawl budget. The nofollow directive on a URL does not prevent a crawler from reaching the page in the same way that another page on your site does.
Use canonical tags to avoid duplicate content issues and to ensure that Googlebot prioritizes crawling the original version of a piece of content.
You can also make use of site auditing tools such as DeepCrawl, OnCrawl, Botify
Ahrefs Site Audit, and SEMRush.
How’s Your Technical SEO?
Hopefully, this article has given you a better understanding of crawl budget.
If you operate on smaller websites, you might not have to worry about the crawl budget of your important pages.
“Crawl budget is not something most publishers have to worry about,” according to Google. Most of the time, if a site has fewer than a few thousand URLs, it will be crawled efficiently.”
However, if you work on large sites, particularly ones that produce pages depending on URL parameters, you may want to prioritize actions that assist Google in determining what to crawl and when.
Crawl budget optimization of s is not for the faint of heart. It becomes critical to examine your technical SEO fitness.
Would you want to discover how well your site’s overall technical SEO is? At Loganix, we have managed SEO services that will assist you to determine what you need to focus on in terms of your SEO and digital marketing strategy.
Feel free to reach out to us today!
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Adam Steele on October 5, 2021
COO and Product Director at Loganix. Recovering SEO, now focused on the understanding how Loganix can make the work-lives of SEO and agency folks more enjoyable, and profitable. Writing from beautiful Vancouver, British Columbia.