




What Is a Robots Meta Tag? Search Engine Directives Explained


It’s often said there are two certainties in this world: death and taxes.
But I’d argue there’s a third: if a search engine can’t crawl and index your website, it ain’t gonna rank—there’s no two ways about it.
Plot twist: what if you don’t want a web page indexed and ranked? The answer, my friend, lies in robots meta tags.
To catch you up to speed, here, you’ll learn:
- What is a robots meta tag—no jargon, just answers.
- Why these snippets of code are important for SEO—beyond just the basics.
- How to use them smartly—practical tips, no fluff.
What Is a Robots Meta Tag?
A robots meta tag is a snippet of HTML code used within web development and search engine optimization (SEO). They act as directs that guide search engine crawlers and algorithms about indexing and caching a web page, essentially acting as a bridge between content and how search engines index and present the page in search results.
Learn more: Interested in broadening your SEO knowledge even further? Check out our SEO glossary, where we’ve explained over 250+ terms.
Robots Meta Tags Name and Content Attributes
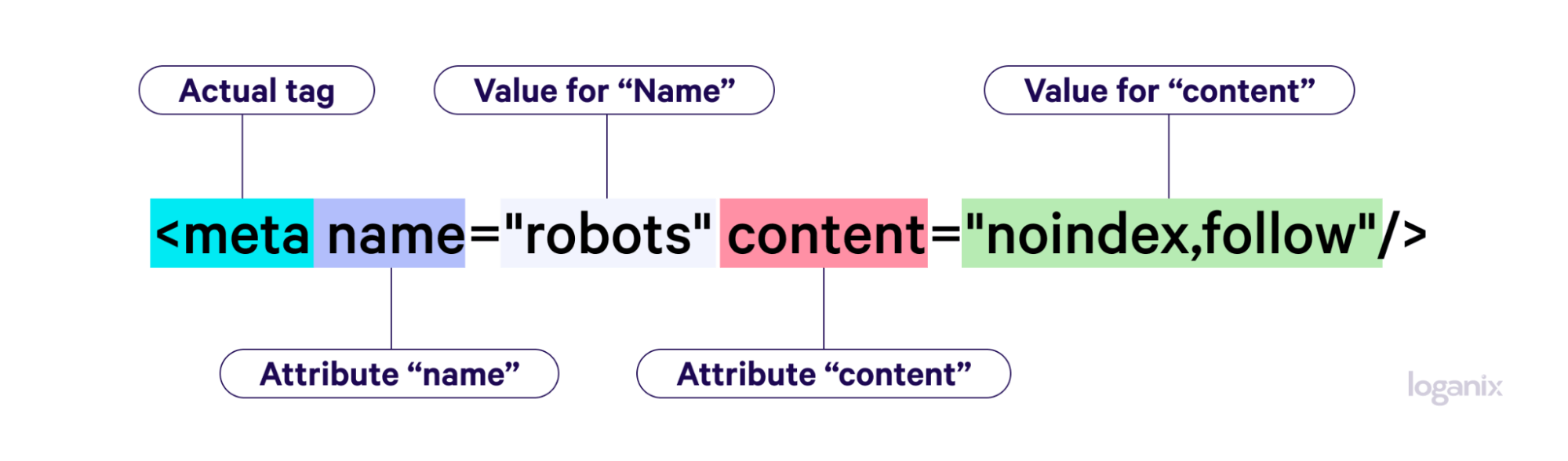
There are two different attributes and values used in robots meta tags: name and content.
The Name Attributes and Values
The “name” attribute, often referred to as a user-agent (UA), communicates with search engine crawlers. A UA is essentially the identity of a crawler requesting a page.
If you wish to collectively speak to all web crawlers—Googlebot, Bingbot, Yandexbot, Amazonbot, etc.—use the UA value “robots.”
However, if you want to single out specific crawlers, you can do so by specifying their unique user-agents. For example, you’d use
- <meta name=”Googlebot-news” content=”noindex”> for Google’s news crawler
- or <meta name=”Bingbot-image” content=”noindex”> for Bing’s image crawler.
The Content Attributes and Values
By default, meaning no robots meta tags have been implemented within the head section of a web page’s HTML, web crawlers index a web page and follow any internal or external links it finds on the page.
You can direct these default processes by using content attributes and values. Here are the commonly used robots meta tags:
| Directive | Description | Example Usage |
| all | No restrictions for indexing or serving. Default value, no effect if listed. | <meta name=”robots” content=”all”> |
| noindex | Prevents the page from being shown in search results. | <meta name=”robots” content=”noindex”> |
| nofollow | Advises against following any links on the page. | <meta name=”robots” content=”nofollow”> |
| none | Equivalent to noindex, nofollow. | <meta name=”robots” content=”none”> |
| noarchive | Prevents showing a cached link in search results. | <meta name=”robots” content=”noarchive”> |
| nositelinkssearchbox | Prevents showing a sitelinks search box in search results for the page. | <meta name=”robots” content=”nositelinkssearchbox”> |
| nosnippet | Stops showing a text or video snippet in search results. | <meta name=”robots” content=”nosnippet”> |
| indexifembedded | Allows indexing of content embedded in another page despite a noindex rule. | <meta name=”robots” content=”indexifembedded”> |
| max-snippet:[number] | Sets a max character limit for textual snippets in search results. | <meta name=”robots” content=”max-snippet:50″> |
| max-image-preview:[setting] | Sets a max image size for previews in search results. | <meta name=”robots” content=”max-image-preview:large”> |
| max-video-preview:[number] | Sets a max length for video snippets in search results. | <meta name=”robots” content=”max-video-preview:10″> |
| notranslate | Prevents offering translations of the page in search results. | <meta name=”robots” content=”notranslate”> |
| noimageindex | Instructs not to index images on the page. | <meta name=”robots” content=”noimageindex”> |
| unavailable_after:[date/time] | Specifies not to show the page in search results after a certain date/time. | <meta name=”robots” content=”unavailable_after: 2023-12-31″> |
Why Are Robots Meta Tags Important?
Let’s get into the real meat of this guide: robots meta tags role and influence on search engine optimization and web development.
Directing the Search Engine Spotlight
Robots meta tags are your tool to guide search engines on how your best SEO content gets noticed while keeping the less important pages out of the limelight. It’s a selective approach that’s key, especially for pages that don’t add much SEO value, like administrative login pages or duplicate content.
Managing Your Site’s Link Landscape
But it’s not just about which pages get seen. Robots meta tags also let you manage how search engines interpret the links on your site. As we touched on earlier, using “nofollow”, for example, tells search engines which links shouldn’t influence your site’s ranking. This is a big deal for controlling where your site’s authority flows and making sure it’s channeled to the pages that really count.
Dodging the Duplicate Content Bullet
Ever heard the saying, “Too much of a good thing”? That’s duplicate content in the SEO world. It confuses search engines and dilutes your link equity—robots meta tags to the rescue.
By flagging duplicate content as “noindex,” you’re telling search engines to ignore these redundant pages, keeping your site’s content unique, relevant, and, most importantly, effective in ranking.
Mastering Your Search Snippets
First impressions matter, especially in search results. With “nosnippet”, you control the narrative. It’s a tag that lets you decide how much (or how little) of your content appears in search previews. It’s like crafting the perfect teaser that entices users to click through, enhancing both user experience and your click-through rates.
Keeping Up with Temporary Content
Got content that’s here today, gone tomorrow? Use robots meta tags like “unavailable_after” to keep your site’s search presence as fresh as your content. This tag is like setting an expiration date for your pages in search results, ensuring that what’s shown is always current and relevant. No more outdated promo pages showing up and confusing your visitors.
Robots Meta Tags FAQ
Q1: What Is the Difference Between Robots.txt and Robots Meta Tags?
Answer: While robots meta tags dictate whether to index a page, follow links, or store a cached version, a robots.txt file is a broader directive that resides in the root directory of a website, guiding search engine crawlers on which parts of your site you’d like them to access and crawl. It’s true that robots.txt doesn’t have the granularity of meta tags, but it is very useful in steering crawlers away from large sections of a website.
Q2: Can Robots Meta Tags Be Used for Images and PDFs?
Answer: Robots meta tags are specifically for HTML pages, so they can’t be directly used for images or PDFs. To control indexing for these file types, use the X-Robots-Tag in the HTTP header.
Q3: What Is the Best Practice for Using Robots Meta Tags on a Website?
Answer: The best practice is to use robots meta tags selectively and strategically: noindex for private or duplicate content and nofollow for untrusted or irrelevant links. Always ensure they’re correctly placed in the <head> section of your HTML for maximum effectiveness.
Conclusion and Next Steps
Let’s be real, the world of search is ever-changing, making SEO a lot more complex than simply understanding search engine directives.
That’s where Loganix steps in. Whether you’re looking to fine-tune your website’s interaction with search engines, boost your rankings, or just need a guiding hand in the vast SEO landscape, our team has got your back.
🚀 Swing by our SEO services page, and let’s start this journey together. 🚀
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Brody Hall on January 19, 2024
Content Marketer and Writer at Loganix. Deeply passionate about creating and curating content that truly resonates with our audience. Always striving to deliver powerful insights that both empower and educate. Flying the Loganix flag high from Down Under on the Sunshine Coast, Australia.