




What Is A Crawl Error?


Making sure Google can crawl and index your material is the first step toward ranking at the top of search results. It is unable to index the information when it can’t correctly open a page or go from one page to another. These are referred to as crawl errors.
Google has released a substantial amount of data that promises to be highly beneficial to SEOs. We’ve grown to rely on Search Console more than ever before as we’ve long lost adequate keyword data in Google Analytics. The sections “Search Analytics” and “Links to Your Site” are two of the most important elements that were not present in the previous Webmaster Tools.
While we may never be entirely happy with Google’s tools and may occasionally call their bluff, they do provide some useful information (from time to time). Google, to their credit, has created additional help documents and support tools to assist Search Console users in identifying and fixing crawl errors.
This article will help you understand what crawl error is, why it’s bad, how to fix Google crawl errors, what is meant by crawl error in SEO, and how to fix URL problems.
Let’s get right into it.
What Is a Crawl Error?
Crawl errors occur when a search engine attempts but fails to access a page on your website.
Let’s throw some additional light on crawling first. Crawling is the procedure of a search engine trying to visit every page of your website through a bot. A search engine bot finds a link to your website and proceeds to find all your public pages from there.
The bot crawls the pages and indexes all the information for use in Google, plus adds all the links on these pages to the pile of pages it still has to crawl. Your major aim as a website owner is to make sure the search engine bot can get to all your important pages on the site. Failing at this procedure yields what we call crawl errors.
Google categorizes crawl errors into two:
- URL errors: You don’t want them but because they only refer to one URL per error, they are easier to maintain and correct.
- Site errors: You don’t want them either since they prevent your full site from being indexed.
Let us expand on these a bit.
URL errors
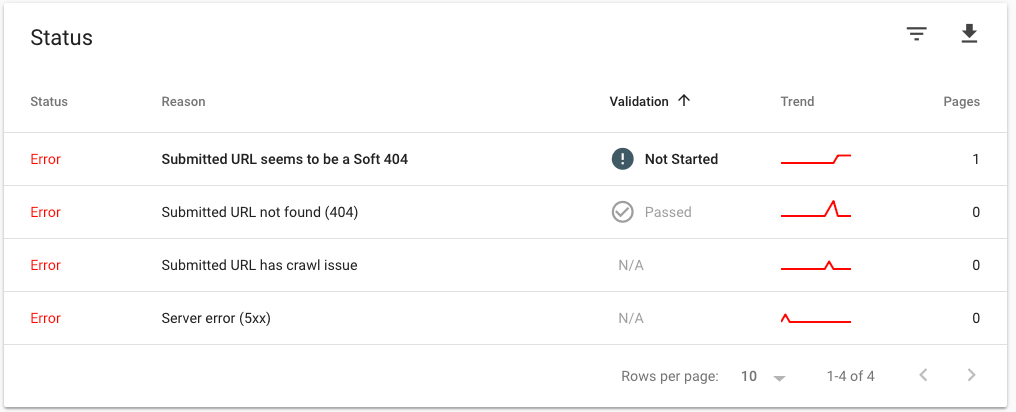
URL errors, as previously stated, are crawl errors that occur when a search engine bot attempts to crawl a certain page of your website. When we talk about URL errors, we usually start with crawl errors like (soft) 404 Not Found error codes.
Please use a 301 redirect instead if you have duplicate content on another page. Obviously, make sure your sitemap and internal links are up to date as well. In fact, according to research, redirected pages account for 16% of all queries.
An occasional DNS error or server error for that individual URL might be among these frequent errors. Check that URL again later to see if the error has gone away. If you’re using Google Search Console as your primary monitoring tool, be sure to utilize Fetch as Google tool and mark the error as rectified.
Site errors
All crawl errors that prohibit the search engine bot from visiting your website are referred to as site errors. There are several causes for this, the most prevalent of which are:
- Server connectivity errors: If your Google Search Console displays server errors, this indicates that the bot was unable to reach your website. The request may have expired. The search engine (for example) attempted to access your website, but it took so long to load that the server response was an error message. Many of these errors are returned as 5xx status codes, such as 500 and 503. Timeouts, truncated headers, truncated responses, rejected connections,, connection refused, and no responses are all examples of server connectivity errors.
- DNS (Domain Name System) errors: This implies that a search engine cannot interact with your server. For example, if your DNS server is down, your website cannot be accessed. This is generally only a temporary problem. Google will return to your website later and crawl it anyhow. This indicates that Googlebot was unable to connect to your domain due to a DNS lookup or DNS timeout issue. If you are experiencing recurring DNS errors, contact your DNS provider.
- Robots failure: Before crawling, Googlebot, for example, attempts to browse your robots.txt file to determine if there are any sections of your website that you would like not to have indexed. If that bot is unable to access a robots.txt file, Google will postpone the crawl until it is able to access the robots.txt file. As a result, always ensure that it is available.
Monitoring the Crawl Errors Report ensures that your domain is free of broken links, which will improve your Search Engine Optimization (SEO) performance.
Why Are Crawl Errors Bad?
The most obvious issue with having a high number of crawl errors on your site is that these errors prevent Google from accessing your content. Google cannot rank pages that they are unable to access.
A large number of crawl errors can have an impact on how Google perceives the overall health of your website. When Google’s crawlers encounter several difficulties accessing a site’s content, they may determine that those specific pages aren’t worth indexing on a regular basis. As a result, your new pages will take far longer to enter the Google index than they would otherwise.
Crawl Error FAQ
How do I fix Google crawl errors?
A Google crawl error occurs when Googlebot cannot crawl the website because access is denied. Googlebot, unlike a 404, is prevented from indexing the website in the first place.
This means that Googlebot is frequently blocked by Access Denied errors because:
- You need people to log in to view a URL on your site.
- Your robots.txt file prevents Googlebot from accessing certain URLs, whole directories, or your entire site.
- Your hosting provider is preventing Googlebot from accessing your website, or the server needs users to log in through proxy.
How to fix
- Examine your robots.txt file to check that the pages mentioned there are intended to be crawled and indexed. This is a serious problem since incorrectly set robots.txt files might disallow important pages on your site from being indexed.
- To resolve access prohibited errors, delete the piece that is preventing Googlebot access.
- Remove any login prompts from pages you want Google to crawl, whether they are in-page or popup.
- To view how your site appears to Googlebot, use a user-agent switcher plugin for your browser or the Fetch as Google tool.
- To view warnings in your robots.txt file and test specific URLs against it, use the robots.txt tester.
- Screaming Frog will scan your website and urge you to log in to sites that require it.
While not as prevalent as 404 errors, access denied issues can nevertheless have a negative impact on your site’s rating if the wrong sites are banned. Keep an eye out for these errors and address any serious concerns as soon as possible.
What is meant by crawl in SEO?
Crawling is the process by which Google or another search engine sends a crawler to a web page or web post to “read” it. This is how Googlebot and other crawlers determine what is on a page. Don’t get this mixed up with getting that page crawled. Crawling is the initial step in having a search engine identify and display your website in search results.
However, having your page crawled does not always imply that it has been (or will be) indexed. To be found in a search engine query, you must first be crawled and then indexed.
How does Google know to check your page once it is generated or updated?
Crawling occurs for a variety of causes, including:
- Submitting an XML sitemap to Google with the URLblocked by the noindex tag
- Increasing the amount of traffic to the page
- The presence of internal links linking to the page
- The presence of external links linking to the page
To guarantee that your page is indexed, publish an XML sitemap to Google Search Console (formerly Google Webmaster Tools), to provide Google with a roadmap for all of your new content.
Crawling indicates that Google is taking a look at the page. Depending on whether Google believes the content is “new” or has anything to “give to the internet,” it may be scheduled to be indexed, which implies it has the potential to rank.
When Google crawls a website, it also looks at the links on that page and schedules the Googlebot to visit those pages as well. The only exception is when the link contains a nofollow tag.
How do I fix the “submitted URL has crawl issue” error?
A crawl issue indicates that a page is having issues and that Google is unable to index it. You must determine the source of the problem, correct it, and resubmit the page to Google.
The first step is to choose Inspect URL from the drop-down menu.
Then, from the right menu, select View Crawled Page and More Info.
One of the most typical reasons for crawl difficulties is that some of the website’s resources (images, CSS, JavaScript) were unable to load when Google attempted to index the page.
Before you go any further, you should:
- Visit the website in a new browser window. If it loads normally, the errors were most likely only transitory.
- To compel Google to update the error report, click the Test Live URL button.
- Double-check the information.
- To re-submit the page to Google, click the Request Indexing button.
- Return to the Index Coverage Report and the problematic page, and then click the Validate Fix button.
Google will be forced to recrawl the URL as a result of this.
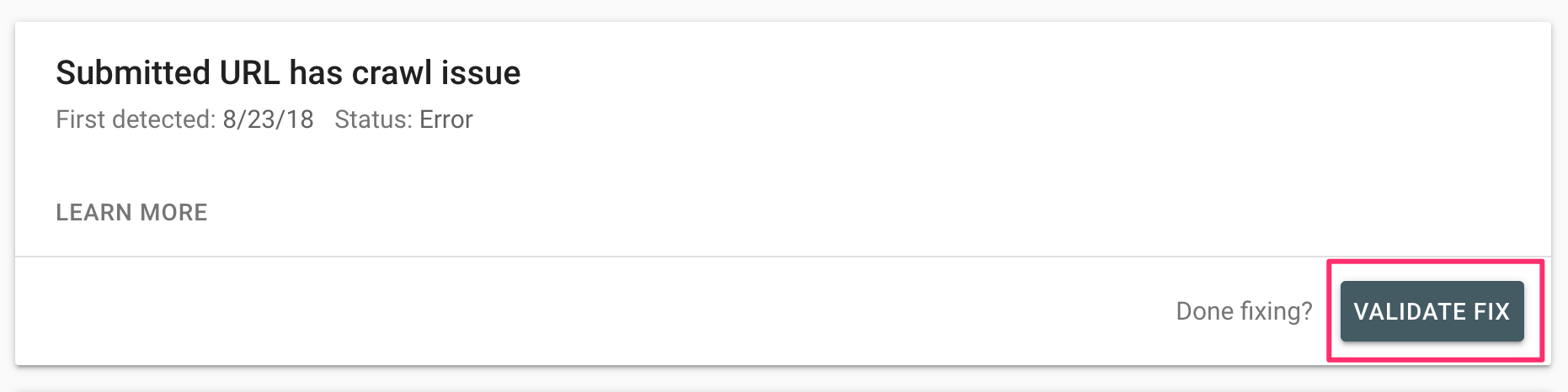
If you continue to receive errors or resources that are not found after clicking the Test Live URL button, you should first repair the errors by modifying your HTML Code, and then request indexing and verifying the change.
How do I fix URL problems?
The following are three of the most common URL errors. If your site is experiencing one or more of these issues, have a look at these remedies and get them resolved as soon as possible.
Problem #1: Duplicate URLs for the home page
This is similar to Problem #2, but it’s worse because it’s your home page. It is possible to have a huge number of different URLs that all lead to the same information on your home page, especially if you haven’t addressed your www and non-www duplication, which may result in a lot of needless duplication. As an example:
- http://www.mysite.com
- http://mysite.com
- http://www.mysite.com/index.html
- http://mysite.com/index.html
All of these URLs will link to the same page. There will be a four-way split in link value if you have links pointing to all four of them.
The Fix
Here are a few pointers:
- Set the URL of your primary home page to http://www.mysite.com. Because this is the most basic URL, 301 redirect everything else to it. (If you want a non-www URL format, use http://mysite.com.)
- If you need to create several versions for tracking or other reasons, use a canonical tag to tell search engines which version you want to appear in search results.
- When creating connections to your home page, make sure you link to the proper version.
Problem #2: Differences between non-www and www versions of site URLs
If every URL on your site has both a non-www and a www version, you’ll be dividing link value for the same content between two URLs. Rather than collecting 100 percent of the link value on the page you wish to rank in search results, you might split it 50/50, 60/40, or in some other way across the two URLs.
The Fix
- Choose whether you wish to utilize www or non-www URLs.
- Create a 301 redirect so that any old URLs to your non-preferred URL style will be redirected to the correct style. By dividing the link value across two URLs, you avoid wasting it.
- Set your chosen domain in Google Webmaster Tools so that your search result listings reflect your preferred style.
- Make sure to utilize the specified URL style anytime you create links to your site.
Problem #3: Dynamic URLs
This is a fun one that many non-SEO-friendly shopping cart applications encounter. When you start putting all kinds of variables and parameters in your URLs, the possibilities for duplicate content and squandered link value become limitless.
Other factors might contribute to the dynamic URL error. Many businesses utilize parameter-based URLs for statistics purposes. We just want to make sure you don’t shoot yourself in the foot in terms of SEO.
The Fix
- If at all feasible, use SEO-friendly base URLs for your site. It is preferable to have a basic URL that leads to the content rather than a URL that is dependent on a parameter.
- Set a canonical tag to instruct search engines to use the URL’s base version. You may still obtain your data using parameter URLs like http://www.mysite.com/unique-product.html?param1=123¶m2=423, but search engines will regard the simple version to be the legitimate one.
- An even better solution is to capture the data on the server-side and then redirect the user to the right URL after the data has been obtained.
- To avoid malware attacks, keep your protection subscriptions up to date.
Fix Your Crawl Errors
Hopefully, this article has given you a better understanding of crawl errors.
Internal crawl errors and needless redirects have an impact on user experience and crawlability, and ultimately your rankings.
We understand that some of this technical SEO jargon might bore you to tears. Nobody likes to check seemingly little URL errors individually or have a panic attack when they discover thousands of errors on your site.
However, with practice and repetition, you will develop the mental muscle memory of understanding how to react to errors: which are critical and which can be safely disregarded. It’ll become second nature very quickly.
If you haven’t already, I recommend reading through Google’s official Search Console instructions.
Alternatively, you can reach out to us to help you with your SEO needs.
Hand off the toughest tasks in SEO, PPC, and content without compromising quality
Explore ServicesWritten by Aaron Haynes on October 6, 2021
CEO and partner at Loganix, I believe in taking what you do best and sharing it with the world in the most transparent and powerful way possible. If I am not running the business, I am neck deep in client SEO.